WebScraping(BeautifulSoup) with Python
I am Christian,a Python developer, Content Creator from Hashnode. A Computer Engineering Student who loves Coding, Sharing of knowledge, Interacting with poeple. Also play Basketball, Music, Sweets etc
- What is Web Scraping?
- BeautifulSoup
- Getting Everything Set
- Let's Work with an Example
- find_all and find functions
- Conclusion
What is Web Scraping?
Web scraping is the process of using bots to extract content and data from a website. Unlike screen scraping, which only copies pixels displayed onscreen, web scraping extracts underlying HTML code and, with it, data stored in a database.
BeautifulSoup
Beautiful Soup is a Python library designed for quick turnaround projects like screen-scraping. Three features make it powerful:
Beautiful Soup provides a few simple methods and Pythonic idioms for navigating, searching, and modifying a parse tree: a toolkit for dissecting a document and extracting what you need. It doesn't take much code to write an application.
Beautiful Soup automatically converts incoming documents to Unicode and outgoing documents to UTF-8. You don't have to think about encodings, unless the document doesn't specify an encoding and Beautiful Soup can't detect one. Then you just have to specify the original encoding.
Beautiful Soup sits on top of popular Python parsers like lxml and html5lib, allowing you to try out different parsing strategies or trade speed for flexibility. For more click here.
Getting Everything Set
Now let's start writing some lines of code. We are going to import 02 libraries Beautifulsoup and requests.
from bs4 import Beautifulsoup
import requests
The requests Library is a python library used for making HTTP request from a server inorder to generate the HTML code of a specific website passed as a parameter. Click here to learn more.
If you are unable to import the bs4(Beautifulsoup4) library make sure you install it.
$ pip install beautifulsoup4
#Also do same for the requests library
$ pip install requests
Let's Work with an Example
We will use this Commercial Booking Website books.toscrape.com So let's start.
This is an image of the website we will scrape
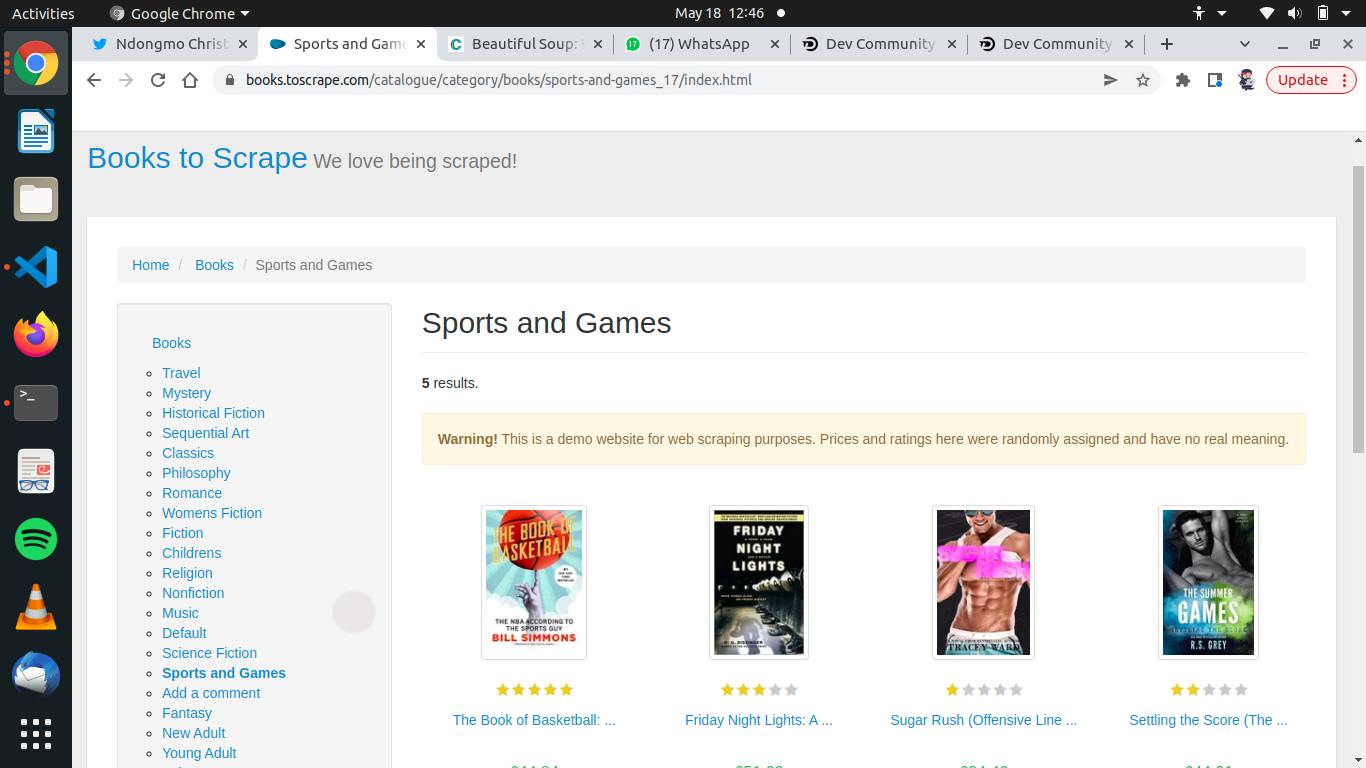 .
.
html_text = request.get('https://books.toscrape.com/catalogue/category/books/sports-and-games_17/index.html').text
print(html_text)
In the code above we are using the get function from the requests library, which takes a parameter the link address of the website we want to scrape.
Then the .text is used at the end of the line to return only text(html lines) found inside the code. Printing html_text we get the html source code as follows.
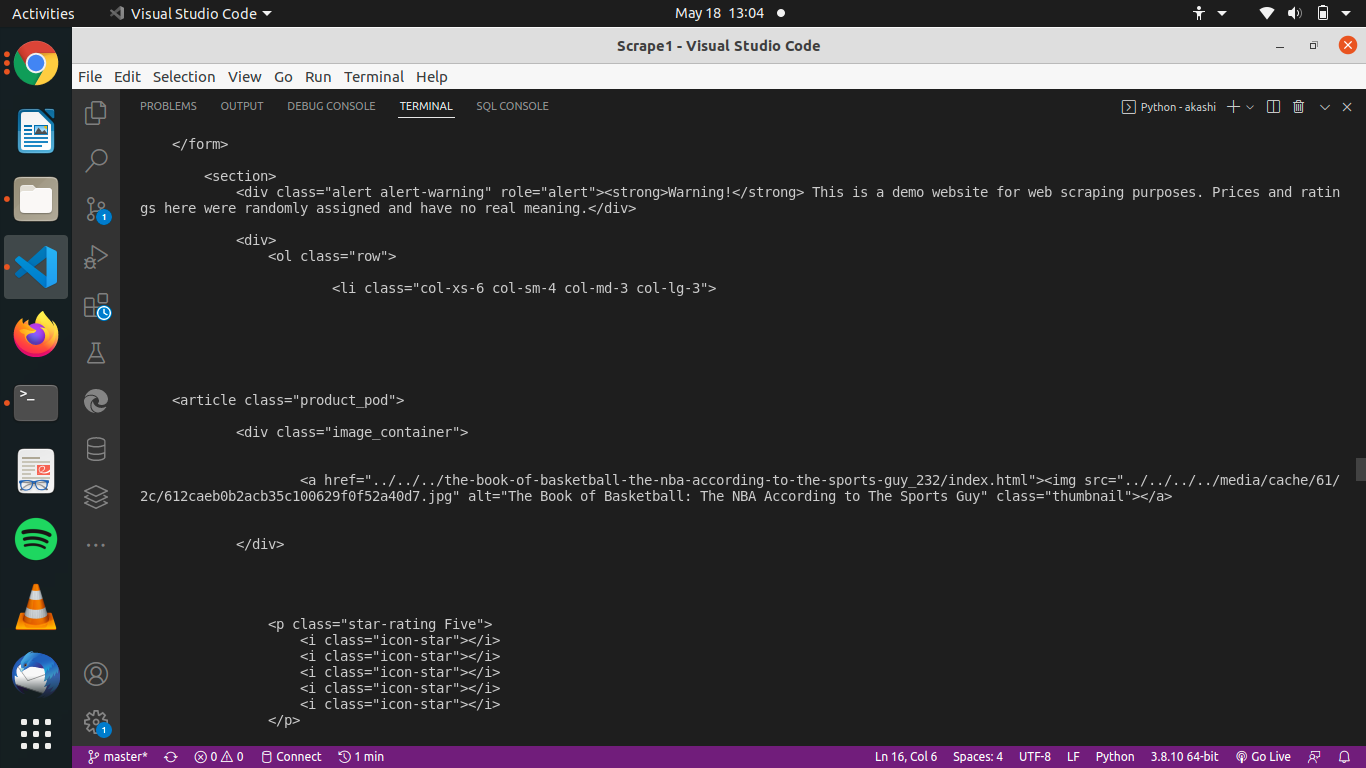
Now let's create an object from the Beautifulsoup class. From this object we will be able to make some research on the html code we requested earlier. let's create an instance of Beautifulsoup class.
soup = Beautifulsoup(html_text, 'lxml')
#lxml is a python library which facilitates the handling of xml and html languages
#so lxml will help us handle scraping more easily.
From here soup handles the code of the url passed in the get method. As you can imagine all our scraping will carried out using soup.
Find_all and Find functions
We want to scrape the name of the first book, in the list of books on the website. This is what we are to do.
- select the name of book
- right click on it
- take the option
inspect - from there we get the class name and the html tag
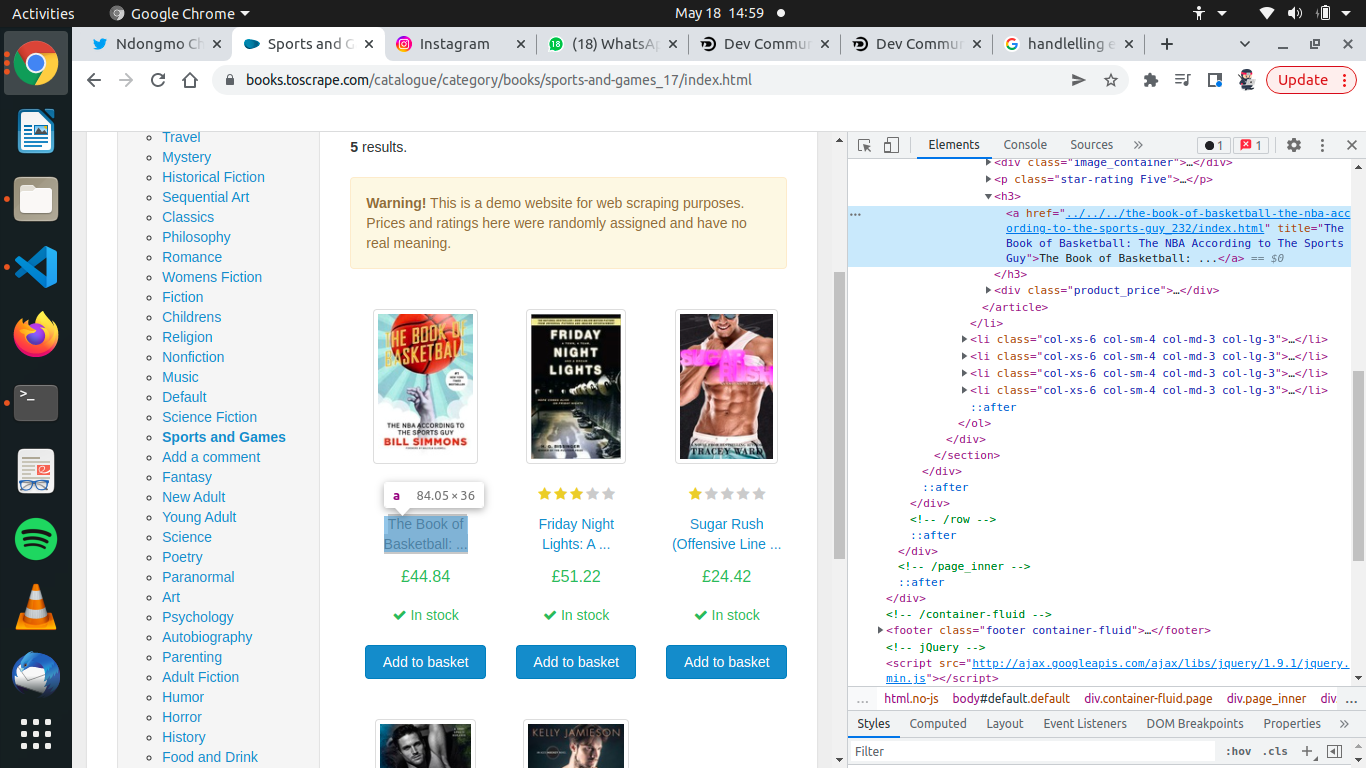 The class holding this name is
The class holding this name is class = product_pod and it is found inside an a html tag. Using now the find() function which take the both the html tage where the book name is found and the class name of the html tag. This is a simple example
#for find()
book = soup.find('li', class_='col-xs-6 col-sm-4 col-md-3 col-lg-3')
#here the variable book holds all the information held by the the first book on the website. Find returns only the first element it finds.
#for find_all()
books = soup.find_all('li', class_='col-xs-6 col-sm-4 col-md-3 col-lg-3')
#Here we return all the elements having that class and contains an html tag <li>. So here all the books are stored inside the books variable.
Finding the Book name
Now we can scrape the name using the find method still. The find methos will be used on the book variable this time to get the book name.
#No need specifying the class in this case
book_name = book.find('h3').text
#Output
#The Book of Basketball: ...
Congratulations you just scraped a website.
Conclusion
This aricle is just an introduction to web Scraping . If you want to learn more about it, visit the freecodecamp YouTube. To see the complete code for this article visit my Github account For more follow me on Twitter. Please Comment, Like and Share.
